Hola a todos!!

He estado un rato dándole vueltas a si debería haber llamado a esta entrada: «Una herramienta para monitorizarlo todo…» así rollo señor de los anillos, pero luego he pensado que lo mismo era más fácil de encontrar si el título no era tan freak, debe ser que me hago viejo…
Pero bueno, como con la imagen si puedo jugar, le he pedido a ChatGPT que la genere con ese espíritu (como el resto de imágenes de cada post) y tengo que decir que me encanta el resultado.
Dicho esto, vamos al tema. Esta entrada será la primera puramente técnica, así que no asustarse, ya volveremos a las entradas menos techies más adelante.
Quiero aprovechar para mencionar un par de referencias, en primer lugar la documentación oficial de Microsoft para este tema (https://learn.microsoft.com/en-us/purview/archive-chatgpt-interactions) y el post en el blog de la comunidad de seguridad de Jon Nordstrom (https://techcommunity.microsoft.com/blog/microsoft-security-blog/unlocking-the-power-of-microsoft-purview-for-chatgpt-enterprise/4371239) que realmente es bastante más util que la documentación, pero aun así nos hemos encontrado con algunos desafíos que os explicaré por si consigo ahorraros dolores de cabeza.
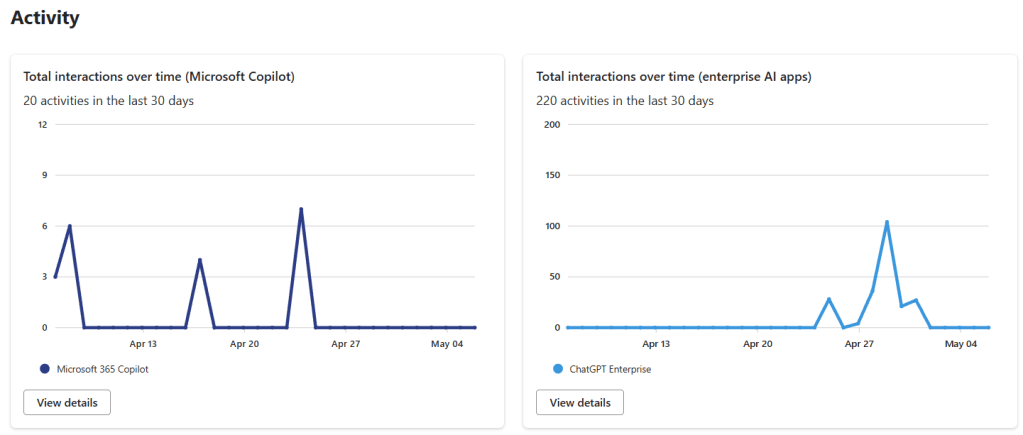
Bien, aquí el objetivo es poder monitorizar las interacciones con ChatGPT Enterprise con Purview, igual que hacemos con Copilot, y además ser capaces de investigar esas interacciones con eDiscovery. El punto es que para conseguirlo, Microsoft ha decidido hacer esta integración utilizando las capacidades de Purview Data Map, que hasta hace bien poco era Azure Data Map, y cuya integración esta todavía un pelín verde en Purview, así que vamos a tener que hacer unas cuantas cosas divertidas, pero lo que queremos conseguir es esto:
Para ello, los pasos de registro y creación del workspace de ChatGPT están bastante bien explicados en la documentación de Microsoft, y sobre todo en el post de Jon, podéis seguirlos sin mucho problema, así que no voy a replicar toda esa parte aquí. Donde nos hemos encontrado con más problemas ha sido en la parte de asignación de permisos que, de hecho no genera ningún error si os la saltáis, simplemente los datos no aparecen en el DSPM for AI de purview, así que esta es la parte que voy a explicar con más detalle.
En primer lugar para que todo esto funcione tenemos que tener una cuenta de Purview de tipo Enterprise, es decir, asociada a una subscripción de azure, porque toda esta monitorización, al tratarse de un sistema externo a Microsoft 365, tiene un cierto coste, no es muy elevado, pero está ahi. La información para configurar esta cuenta la tenéis aqui: https://learn.microsoft.com/en-us/purview/purview-payg-subscription-based-enablement
Una vez tengamos la cuenta, el siguiente paso es darle permisos para que pueda acceder a la API de Purview y de Graph, y aquí es donde hemos encontrado la mayoría de los problemas, así que voy a intentar explicarlo todo lo facil que pueda.
Lo primero que necesitamos es el «ObjectID» de nuestra cuenta de purview, que vamos a suponer que se llama «purview-account» y para efectos de esta demo que el mío es «11111111-aaaa-bbbb-cccc-123456789abc». Para obtener ese ID podemos o bien entrar en el portal de Azure tal como explica Jon en su post, o buscarlo como buscaremos más adelante los otros ID, utilizando el comando Get-MgServicePrincipal, con un filtro:
Get-MgServicePrincipal -Filter "StartsWith(DisplayName, 'PurviewAccount')"De esta cuenta necesitamos el Id, no el AppID, cuando ejecutemos el comando, nos va a devolver algo parecido a esto:

Ese Id es lo que tenemos que guardar: 11111111-aaaa-bbbb-cccc-123456789abc
Lo siguiente que vamos a necesitar son los ID de los recursos sobre los que vamos a dar los permisos, que cambian para cada tenant, y que tenemos que obtener en base al nombre de los recursos, o al ID que es fijo y que están en el post del blog de Jon, por lo que podemos utilizar esos comandos directamente (el primero para Purview, el segundo para Graph):
(Get-MgServicePrincipal -Filter "AppId eq '9ec59623-ce40-4dc8-a635-ed0275b5d58a'").id
(Get-MgServicePrincipal -Filter "AppId eq '00000003-0000-0000-c000-000000000000'").id
O podemos utilizar los nombres de los recursos que serían:
- «Purview Ecosystem» para la API de purview
- «Microsoft Graph» para la API Graph


Como podéis ver en estos casos el AppId coincide con los del post de Jon, pero si queréis estar seguros, el nombre si que es común en todas los tenants. Con esto ya tendríamos los dos ID de los recursos que necesitamos:
- API Purview: 22222222-aaaa-bbbb-cccc-123456789abc
- API Graph: 33333333-aaaa-bbbb-cccc-123456789abc
Ya únicamente faltarían los roles que queremos asignar, que son:
- Purview.ProcessConversationMessages.All en la API de Purview (GUID a4543e1f-6e5d-4ec9-a54a-f3b8c156163f)
- User.Read.All en la API Graph (GUID df021288-bdef-4463-88db-98f22de89214)
Podéis buscar los GUID en vuestro tenant si no estáis seguros, pero estos no cambian, por lo que debería ser seguro utilizar los que os pongo aquí, de todas formas si queréis buscarlos por seguridad, estos comandos os pueden ayudar:
$app = Get-AzureADServicePrincipal -ObjectId 22222222-aaaa-bbbb-cccc-123456789abc
$app.AppRoles | Where-Object -Property Value -eq 'Purview.ProcessConversationMessages.All'
$app = Get-AzureADServicePrincipal -ObjectId 33333333-aaaa-bbbb-cccc-123456789abc
$app.AppRoles | Where-Object -Property Value -eq 'User.Read.All'Con esta información ya podemos asignar los roles. En el post de Jon utiliza el comando New-MgServicePrincipalAppRoleAssignment, pero nosotros hemos utilizado New-AzureADServiceAppRoleAssignment, os dejo las dos opciones. Con el primero podemos crear una variable con los parámetros y con el segundo tendremos que incluir los parámetros uno a uno. Cuidado porque tanto en el blog de Jon como en la documentación aparecen algunas llaves por ahí que a nosotros nos han dado problemas. Así quedarían los comandos con los GUID ficticios que tenemos
Usando Graph
$params = @{
principalId = "11111111-aaaa-bbbb-cccc-123456789abc"
resourceId = "22222222-aaaa-bbbb-cccc-123456789abc"
appRoleId = "a4543e1f-6e5d-4ec9-a54a-f3b8c156163f"
}
New-MgServicePrincipalAppRoleAssignment -ServicePrincipalId $servicePrincipalId -BodyParameter $params
$params = @{
principalId = "11111111-aaaa-bbbb-cccc-123456789abc"
resourceId = "33333333-aaaa-bbbb-cccc-123456789abc"
appRoleId = "df021288-bdef-4463-88db-98f22de89214"
}
New-MgServicePrincipalAppRoleAssignment -ServicePrincipalId $servicePrincipalId -BodyParameter $paramsUsando AzureAD
New-AzureADServiceAppRoleAssignment -ObjectId '11111111-aaaa-bbbb-cccc-123456789abc' -PrincipalId '11111111-aaaa-bbbb-cccc-123456789abc' -ResourceId '22222222-aaaa-bbbb-cccc-123456789abc' -Id 'a4543e1f-6e5d-4ec9-a54a-f3b8c156163f'
New-AzureADServiceAppRoleAssignment -ObjectId '11111111-aaaa-bbbb-cccc-123456789abc' -PrincipalId '11111111-aaaa-bbbb-cccc-123456789abc' -ResourceId '33333333-aaaa-bbbb-cccc-123456789abc' -Id 'df021288-bdef-4463-88db-98f22de89214'De esta forma nuestra cuenta de purview debería tener los permisos necesarios para que las interacciones con ChatGPT Enterprise empiecen a aparecer en el DSPM for AI y en el Activity Explorer. También podremos encontrarlas con eDiscovery e incluso utilizarlas en Communication Compliance e Insider Risk Management.
OJO!! que esta no es toda la configuración, aun tendríamos que configurar el Key Vault para almacenar las claves de ChatGPT enterprise como se indica en esta documentación. Y añadir el data source al Purview Data map, tal como se explica en el post de Jon, para lo que vais a necesitar información que os debería proporcionar OpenAI. Finalmente hay que configurar los escaneos para que incorporen la información generada por ChatGPT Enterprise en Purview.
Espero que esta entrada os ayude a resolver configurar la integración más fácilmente!
Un Saludo!!